import mikeplus as mp
db = mp.open("data/Dyrup_uncalibrated.sqlite")
print(f"MIKE+ Database Version: {db.version}")
db.close()MIKE+ Database Version: 2025.0.0Understanding how MIKE+ stores its data is crucial for effectively using MIKE+Py. This section covers the basics of the MIKE+ database, shows how to explore the database structure both within the MIKE+ GUI and programmatically with MIKE+Py.
This section provides a concise primer on useful background knowledge.
MIKE+ stores model data in an SQLite database, a common and self-contained format.
A single .sqlite file holds all tables and data.
Tables are organized and linked together using keys (unique IDs like MUID).
As open-source software, it requires no installation and works with many tools.
While MIKE+ also supports PostgreSQL databases, MIKE+Py currently only supports SQLite.
SQL (Structured Query Language) is the standard language for managing data in a relational database. You use it to query and modify data with commands like:
Get specific data from tables.
Change, add, or remove data.
Filter data with conditions.
You do not need to know SQL to use MIKE+Py. However, MIKE+Py’s design intentionally mirrors common SQL patterns, so being familiar with the concepts is helpful.
If you’re new to SQL, there are many excellent resources available online. Here are a few starting points:
When you work with a MIKE+ project, you’ll typically interact with two main file types:
The main file you open with MIKE+. It points to the database location and stores UI settings like map symbology, preferences, and background layers.
This file is the model database. It stores all the core model data, including network elements (nodes, links, catchments), their parameters, simulation setups, scenarios, and alternatives.
MIKE+Py works on the project database (.sqlite), not the project file.
Simply open it with any text editor. It uses DHI’s PFS format, which is structured plain-text. For more advanced edits, consider using MIKE IO’s PFS functionality.
The MIKE+ Database organizes tables into groups with the following naming conventions.
| Prefix | Description | Example(s) |
|---|---|---|
m_ |
General MIKE+ tables | m_ModelSetting |
ms_ |
Tables common to collection systems and water distribution | ms_Tab |
mw_ |
Water distribution specific tables | mw_Pipe, mw_Junction |
msm_ |
MIKE 1D collection systems | msm_Node, msm_Link |
mrm_ |
MIKE 1D rivers | mrm_Branch |
mss_ |
SWMM specific tables | mss_Node, mss_Link |
m2d_ |
MIKE 21 specific tables | m2d_Boundary |
Most tables have a MUID column, which serves as a unique identifier for each record (row) within that table.
Refer to MIKE+’s documentation for more detailed descriptions.
Before diving into programmatic access, it’s helpful to know how to identify table and column names using the MIKE+ GUI. This will help you identify the table and column of the data you’re interested in.
The easiest way is with MIKE+’s tooltips. When you hover over a field, a tooltip is displayed containing both the table name and column name. The format is: TableName.ColumnName. For example, the video below shows three different columns that all reside in the table msm_Catchment.
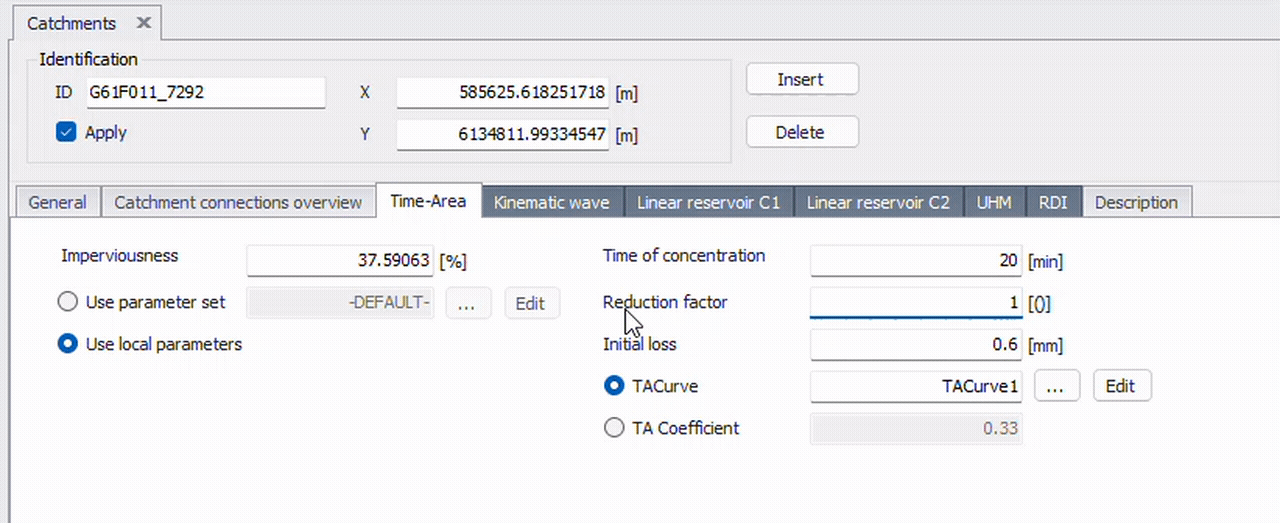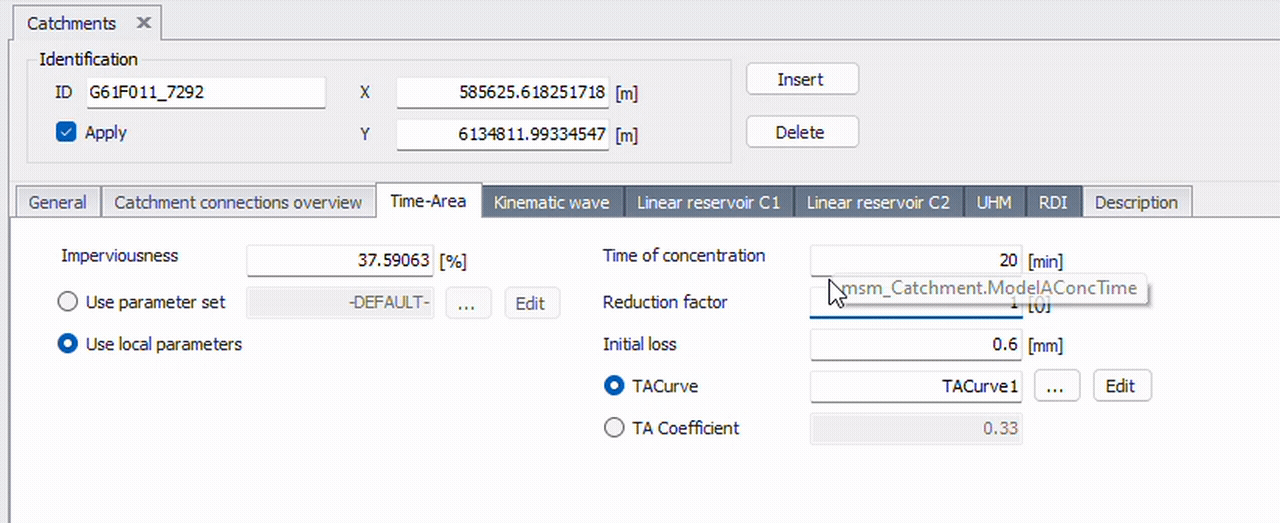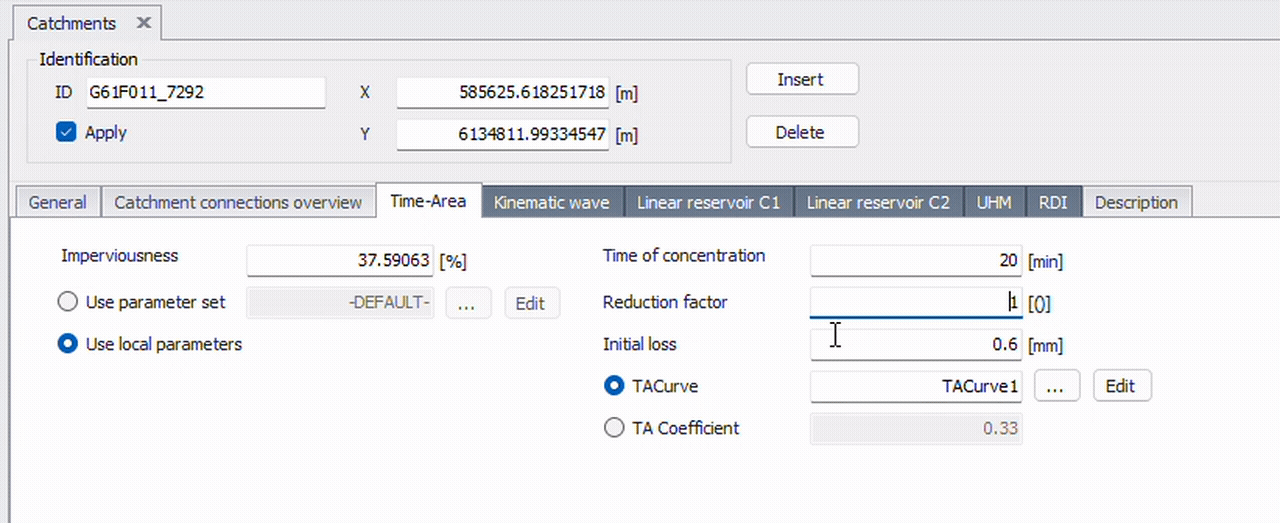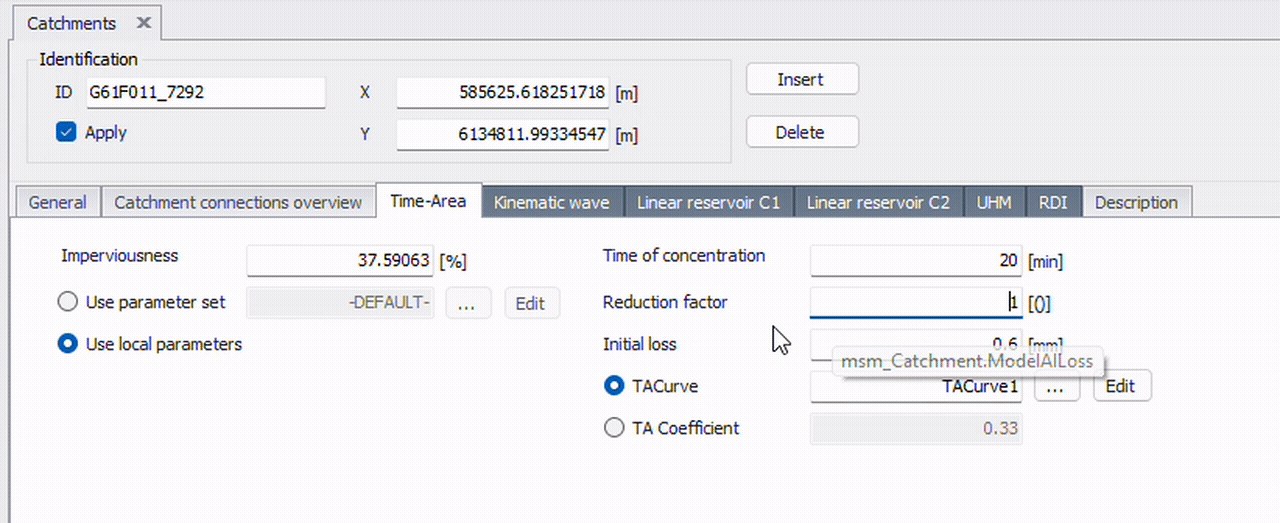
A typical workflow in MIKE+Py is first identifying where the data is via the GUI. This information is essential for querying and modifying specific data.
You can also hover over the column headers in a MIKE+ table view.
First, open a database with mp.open(). This returns a Database object, which is central for all database operations.
import mikeplus as mp
db = mp.open("data/Dyrup_uncalibrated.sqlite")
print(f"MIKE+ Database Version: {db.version}")
db.close()MIKE+ Database Version: 2025.0.0It’s important to close the Database object at the end of your workflow with close().
It’s easy to forget, therefore it’s recommended to use Python’s context manager syntax to handle closing automatically:
with mp.open("data/Dyrup_uncalibrated.sqlite") as db:
print(f"MIKE+ Active Model: {db.active_model}")
# database remains open within this code block...
# now it's closed :)MIKE+ Active Model: CS_MIKE1DThe remaining code examples assume a Database object was obtained per the above examples.
The db.tables attribute provides access to a collection of all tables in the database.
db.tablesTableCollection<323 tables>You can access a specific Table object by attribute-style access. Notice this conveniently includes auto-completion.
db.tables.msm_Catchmentmsm_CatchmentTable<Catchments>We’ll look into working with tables in the next section, but notice it’s integrated with Pandas:
df = db.tables.msm_Catchment.to_dataframe()
df.head()| MUID | Enabled | GeomCentroidX | GeomCentroidY | Area | GeomArea | Persons | HydrologicalModelNo | LossDefinition | ModelAImpArea | ... | SWMM_InitDef | SWMM_Conduct | SWMM_RunoffCN | SWMM_CRegen | SWMM_Tag | DataSource | AssetName | Element_S | NetTypeNo | Description | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| G61F011_7292 | G61F011_7292 | 1 | 585625.618252 | 6134811.993345 | 4501.460376 | 4501.456959 | 0.0 | 1 | 1 | 0.375906 | ... | None | None | 0 | None | None | None | None | None | 3 | D10F050 |
| G61F013_7293 | G61F013_7293 | 1 | 585673.073141 | 6134756.306611 | 2376.508964 | 2376.511229 | 0.0 | 1 | 1 | 0.327839 | ... | None | None | 0 | None | None | None | None | None | 3 | D10F050 |
| G61F030_7294 | G61F030_7294 | 1 | 585564.527279 | 6134874.864836 | 4567.727442 | 4567.727991 | 0.0 | 1 | 1 | 0.416389 | ... | None | None | 0 | None | None | None | None | None | 3 | D10F050 |
| G61F031_7295 | G61F031_7295 | 1 | 585533.822109 | 6134832.92312 | 3759.297083 | 3759.301193 | 0.0 | 1 | 1 | 0.387001 | ... | None | None | 0 | None | None | None | None | None | 3 | D10F050 |
| G61F032_7296 | G61F032_7296 | 1 | 585499.225735 | 6134786.067181 | 5635.766493 | 5635.764436 | 0.0 | 1 | 1 | 0.344482 | ... | None | None | 0 | None | None | None | None | None | 3 | D10F050 |
5 rows × 109 columns
Each table object has a columns attribute that allows you to see the names of its columns. This is mostly useful for auto-completion and avoiding typos.
db.tables.msm_Catchment.columns.ModelAConcTime'ModelAConcTime'
MIKE+ has many tables which can take a few seconds to load on first import. In VS Code, you can open the auto-completion menu with Ctrl+Space, which will indicate it’s loading, then update when finished.
Check out MIKE+Py’s API documentation for a searchable overview of tables and columns.
The next section will dive into more flexible queries of table information.