Creating dfs0 files is a common need for MIKE+ modellers (e.g. rainfall from csv). This section focuses on how to create dfs0 files from a Pandas DataFrame.
15.1 Workflow
The general workflow for creating dfs0 files from a DataFrame is as follows:
Map ItemInfo objects to each column (optional)
Create a Dataset object from the DataFrame
Save the Dataset object to a dfs0 file.
15.2 Example Source Data
The following DataFrame will be used in this section as an example.
import pandas as pddf = pd.read_csv("data/rain_events_2021_july.csv", index_col="time", parse_dates=True)df.head()
rainfall
time
2021-07-02 09:51:00
0.000
2021-07-02 09:52:00
3.333
2021-07-02 09:53:00
0.333
2021-07-02 09:54:00
0.333
2021-07-02 09:55:00
0.333
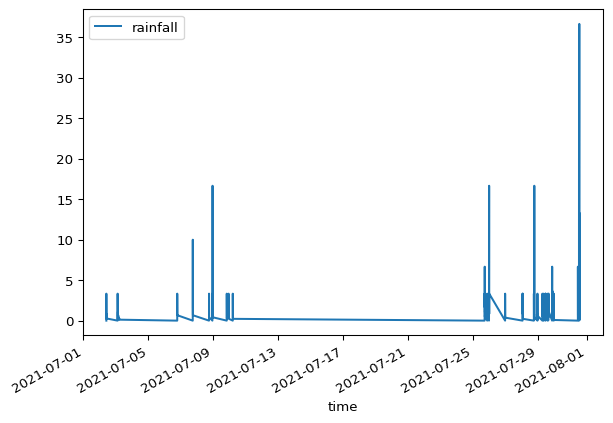
Get familiar with the data. Notice:
The time axis is non-equidistant
Values represent rainfall depth since the last time step.
Rainfall events always start at values of zero.
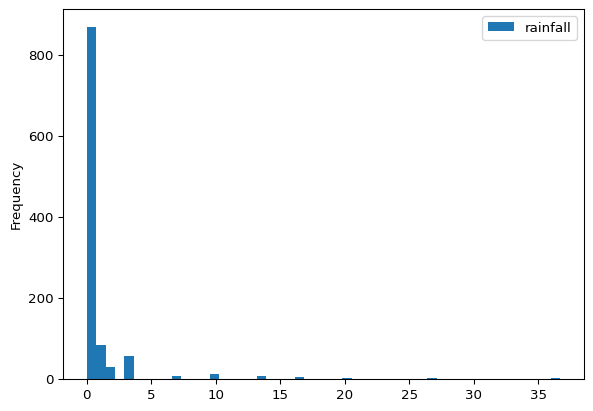
df.describe().T
count
mean
std
min
25%
50%
75%
max
rainfall
1086.0
1.120283
3.219804
0.0
0.185
0.37
0.667
36.667
df.plot()
df.plot.hist(bins=50)
This subset shows the division between two rainfall events:
Ensure your DataFrame’s index is a DatetimeIndex for time series dfs0 files. This is crucial for MIKE IO to correctly interpret the time information.
Notice that the item type and unit are “undefined”. Let’s inspect the ItemInfo MIKE IO used by default:
item = ds[0].itemprint(f"Item Name: {item.name}")print(f"Item Type: {item.type.name}")print(f"Item Unit: {item.unit.name}")print(f"Item Data Value Type: {item.data_value_type.name}")
Item Name: rainfall
Item Type: Undefined
Item Unit: undefined
Item Data Value Type: Instantaneous
This highlights the need to almost always define item metadata before calling from_pandas().
Caution
Providing accurate ItemInfo is key for ensuring compatibility with MIKE software and correctly interpreting the meaning of your data within the MIKE ecosystem.
The final step is to save your carefully prepared Dataset object, now containing the correct data and metadata, to a dfs0 file. This is done using the .to_dfs() method of the Dataset object.
ds.to_dfs("rainfall.dfs0")
This will create a file named rainfall.dfs0 ready to be used in MIKE+.
Confirm it worked by reading the dfs0 file back into a Dataset (optional).