Final assignment#
The final exercise involves converting data from one or more providers.
Since this exercise is designed to prepare you for real project work, the information you need to solve it might be slightly incomplete or not provided in context. Use your best judgment!
Parts of this assignment can be solved in several ways. Use descriptive variable names and comments or descriptive text if necessary to clarify. The final solution should be clear to your colleagues and will be shared with some of your fellow students for review.
The data will be used for MIKE modelling and must be converted to Dfs with apppropriate EUM types/units in order to be used by the MIKE software.
The data is provided as a zip file and a NetCDF file (in the data folder - see FA.3 below).
Inside the zip file, there are a many timeseries (ASCII format) of discharge data from streams located across several regions (*.dat).
Static data for each region is found in a separate file (region_info.csv)
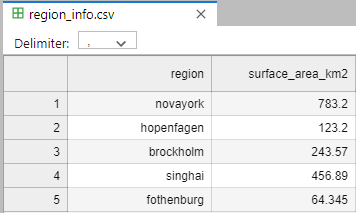
Pandas read_csv is very powerful, but here are a few things to keep in mind
Column separator e.g. comma (,)
Blank lines
Comments
Missing values
Date format
The MIKE engine can not handle missing values / delete values, fill in missing values with interpolated values.
In order to save diskspace, crop the timeseries to simulation period Feb 1 - June 30.
FA.1 Convert all timeseries to Dfs0#
import os
import numpy as np
import pandas as pd
import mikeio
from mikeio import Dataset
from mikeio.eum import EUMType, ItemInfo, EUMUnit
# This is one way to find and filter filenames in a directory
# [x for x in os.listdir("datafolder") if "some_str" in x]
# This is useful!
# help(pd.read_csv)
# example of reading csv
# df = pd.read_csv("../data/oceandata.csv", comment='#', index_col=0, sep=',', parse_dates=True)
a) Convert all timeseries to dfs0 (remember that the notebook should be runnable for your peers so put the files somewhere reasonable).
b) Read s15_east_novayork_river.dfs0, print the “header”, plot, and show that the number of missing values is 0.
FA.2 Add region specific info to normalize timeseries with surface area#
Each timeseries belongs to a region identified in the filename, e.g. s15_east_novayork_river.dat is located in the novayork region.
a) Convert all timeseries to dfs0 with specific discharge, by doing:
For each timeseries in the dataset:
Find out which region it belongs to (hint: the string method split() will be useful)
Divide the timeseries values with the surface area for the region (take into account units)
Create a dfs0 file with specific discharge (discharge / area) (like the one with discharge from FA.1)
b) Determine which station has the largest max specific discharge (in the simulation period).
FA.3 Gridded data#
ERA5 wave model for a part of the North Sea is available in the file "../data/ERA5_DutchCoast.nc"
The dataset is provided in NetCDF
These are the variables of interest:
Significant wave height (Significant height of combined wind waves and swell)
Mean wave direction
Info about spatial and temporal axes can be found in the NetCDF file
import xarray as xr
import mikeio
import numpy as np
ds = xr.open_dataset("../data/ERA5_DutchCoast.nc")
ds
<xarray.Dataset> Size: 590kB
Dimensions: (time: 67, latitude: 11, longitude: 20)
Coordinates:
* time (time) datetime64[ns] 536B 2017-10-27 ... 2017-10-29T18:00:00
* latitude (latitude) float32 44B 55.0 54.5 54.0 53.5 ... 51.0 50.5 50.0
* longitude (longitude) float32 80B -1.0 -0.5 0.0 0.5 1.0 ... 7.0 7.5 8.0 8.5
Data variables:
mwd (time, latitude, longitude) float64 118kB ...
mwp (time, latitude, longitude) float64 118kB ...
mp2 (time, latitude, longitude) float64 118kB ...
pp1d (time, latitude, longitude) float64 118kB ...
swh (time, latitude, longitude) float64 118kB ...
Attributes:
Conventions: CF-1.6
history: 2021-06-07 12:25:02 GMT by grib_to_netcdf-2.16.0: /opt/ecmw...lons = ds.longitude
lats_rev = ds.latitude[::-1] # reversed
# geometry = mikeio.Grid2D(x=...,y=..., projection="LONG/LAT")
#hm0 = mikeio.DataArray(np.flip(...,axis=1),geometry=geometry, time=ds.time, item=mikeio.ItemInfo(...)))
# mds = mikeio.Dataset([...])
a) Find the relevant variables in the NetCDF file.
b) Create MIKE IO DataArrays for each variable
c) Combine the arrays into a MIKE IO Dataset and write it to a dfs2 file
d) Read the data from the file and document that the temporal max at (50N, 1E) of the significant wave height is the same in the dfs2 file as in the NetCDF file (note: due to rounding errors the may not be exactly the same)
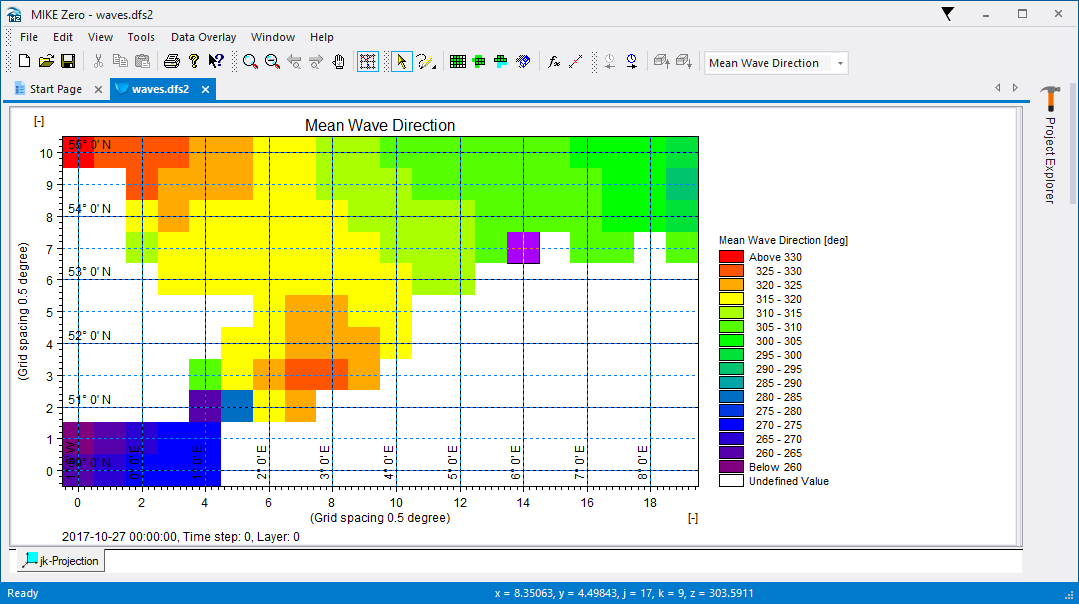
The file should look like this in MIKE Zero:
Submission of solution#
Your solution to the above tasks is to be delivered in the format of a single Jupyter notebook file. Please create a new and name it final_assignment_teamxyz.ipynb where xyz is your team number. It should be easy to understand and runnable by your instructors.
The solution will be reviewed by an instructor, which will provide feedback on both the correctnes and clarity of your solution.
Please submit your team’s solution by email to campus@dhigroup.com.