from mikeio1d import Xns11
xns = Xns11('../data/mikep_cs_demo.xns11')
xns<mikeio1d.Xns11 (103)>Xns11 is the main interface for accessing cross section data.
from mikeio1d import Xns11
xns = Xns11('../data/mikep_cs_demo.xns11')
xns<mikeio1d.Xns11 (103)>Each Xns11 object is a collection of cross sections (CrossSectionCollection) with a file path.
from mikeio1d.cross_sections import CrossSectionCollection
print(xns.file_path)
isinstance(xns, CrossSectionCollection)../data/mikep_cs_demo.xns11TrueAn overview of a cross section collection can be obtained by calling the to_dataframe method.
xns.to_dataframe()| cross_section | |||
|---|---|---|---|
| location_id | chainage | topo_id | |
| basin_left1 | 2.004 | 1 | <CrossSection: basin_left1, 2.004, 1> |
| 33.774 | 1 | <CrossSection: basin_left1, 33.774, 1> | |
| 80.945 | 1 | <CrossSection: basin_left1, 80.945, 1> | |
| 122.042 | 1 | <CrossSection: basin_left1, 122.042, 1> | |
| 166.107 | 1 | <CrossSection: basin_left1, 166.107, 1> | |
| ... | ... | ... | ... |
| tributary | 250.000 | tributary | <CrossSection: tributary, 250.000, tributary> |
| 300.000 | tributary | <CrossSection: tributary, 300.000, tributary> | |
| 400.000 | tributary | <CrossSection: tributary, 400.000, tributary> | |
| 450.000 | tributary | <CrossSection: tributary, 450.000, tributary> | |
| 500.000 | tributary | <CrossSection: tributary, 500.000, tributary> |
103 rows × 1 columns
Cross section collections are dict-like and can be indexed by a tuple of location ID, chainage, and topo ID. The values are CrossSection objects.
xns['basin_left1', '122.042', '1']<CrossSection: basin_left1, 122.042, 1>Alternatively, the location ID, chainage, and topo ID can be explicitly expressed with the sel method.
xns.sel(location_id='basin_left1', chainage='122.042', topo_id='1')<CrossSection: basin_left1, 122.042, 1>Cross section collections can be sliced by location ID, chainage, or topo ID. This returns a list of CrossSection objects.
xns['basin_left1'] # all cross sections at location 'basin_left1'[<CrossSection: basin_left1, 2.004, 1>,
<CrossSection: basin_left1, 33.774, 1>,
<CrossSection: basin_left1, 80.945, 1>,
<CrossSection: basin_left1, 122.042, 1>,
<CrossSection: basin_left1, 166.107, 1>,
<CrossSection: basin_left1, 184.886, 1>,
<CrossSection: basin_left1, 210.212, 1>,
<CrossSection: basin_left1, 264.614, 1>,
<CrossSection: basin_left1, 284.638, 1>,
<CrossSection: basin_left1, 341.152, 1>,
<CrossSection: basin_left1, 413.617, 1>,
<CrossSection: basin_left1, 481.451, 1>]xns[:, '122.042'] # all cross sections at chainage '122.042'[<CrossSection: basin_left1, 122.042, 1>]xns[:,:,'1'] # all cross sections with topo ID '1'[<CrossSection: basin_left1, 2.004, 1>,
<CrossSection: basin_left1, 33.774, 1>,
<CrossSection: basin_left1, 80.945, 1>,
<CrossSection: basin_left1, 122.042, 1>,
<CrossSection: basin_left1, 166.107, 1>,
<CrossSection: basin_left1, 184.886, 1>,
<CrossSection: basin_left1, 210.212, 1>,
<CrossSection: basin_left1, 264.614, 1>,
<CrossSection: basin_left1, 284.638, 1>,
<CrossSection: basin_left1, 341.152, 1>,
<CrossSection: basin_left1, 413.617, 1>,
<CrossSection: basin_left1, 481.451, 1>,
<CrossSection: basin_left2, 29.194, 1>,
<CrossSection: basin_left2, 94.137, 1>,
<CrossSection: basin_left2, 159.062, 1>,
<CrossSection: basin_left2, 214.431, 1>,
<CrossSection: basin_left2, 281.473, 1>,
<CrossSection: basin_left2, 341.557, 1>,
<CrossSection: basin_left2, 398.991, 1>,
<CrossSection: basin_left2, 434.188, 1>,
<CrossSection: basin_right, 0.000, 1>,
<CrossSection: basin_right, 69.014, 1>,
<CrossSection: basin_right, 122.513, 1>,
<CrossSection: basin_right, 182.271, 1>,
<CrossSection: basin_right, 238.800, 1>,
<CrossSection: basin_right, 343.386, 1>,
<CrossSection: basin_right, 403.762, 1>,
<CrossSection: basin_right, 436.489, 1>,
<CrossSection: basin_right, 520.410, 1>,
<CrossSection: basin_right, 563.294, 1>,
<CrossSection: basin_right, 567.166, 1>,
<CrossSection: basin_right, 636.389, 1>,
<CrossSection: basin_right, 662.699, 1>,
<CrossSection: basin_right, 712.468, 1>,
<CrossSection: link_basin_left, 0.000, 1>,
<CrossSection: link_basin_left, 30.000, 1>,
<CrossSection: link_basin_left, 46.000, 1>,
<CrossSection: link_basin_left, 64.000, 1>,
<CrossSection: link_basin_right, 0.000, 1>,
<CrossSection: link_basin_right, 18.000, 1>,
<CrossSection: link_basin_right, 28.000, 1>,
<CrossSection: link_basin_right, 41.930, 1>,
<CrossSection: link_basin_right, 70.870, 1>,
<CrossSection: link_basin_right, 80.400, 1>]Cross section collections can be combined into a new collection.
sections = [*xns['basin_left1', '2.004'], *xns['basin_left1', '210.212']]
new_collection = Xns11(sections)
new_collection.to_dataframe()| cross_section | |||
|---|---|---|---|
| location_id | chainage | topo_id | |
| basin_left1 | 2.004 | 1 | <CrossSection: basin_left1, 2.004, 1> |
| 210.212 | 1 | <CrossSection: basin_left1, 210.212, 1> |
A new cross section can be added to a collection with the add method.
xs_to_add = xns.sel(location_id='basin_left1', chainage='33.774', topo_id='1')
new_collection.add(xs_to_add)
new_collection.to_dataframe()| cross_section | |||
|---|---|---|---|
| location_id | chainage | topo_id | |
| basin_left1 | 2.004 | 1 | <CrossSection: basin_left1, 2.004, 1> |
| 210.212 | 1 | <CrossSection: basin_left1, 210.212, 1> | |
| 33.774 | 1 | <CrossSection: basin_left1, 33.774, 1> |
A cross section is uniquely identified by its location ID, chainage, and topo ID.
xs = xns['basin_left1', '122.042', '1']
xs<CrossSection: basin_left1, 122.042, 1>Cross sections can be plotted directly with the plot method.
xs.plot()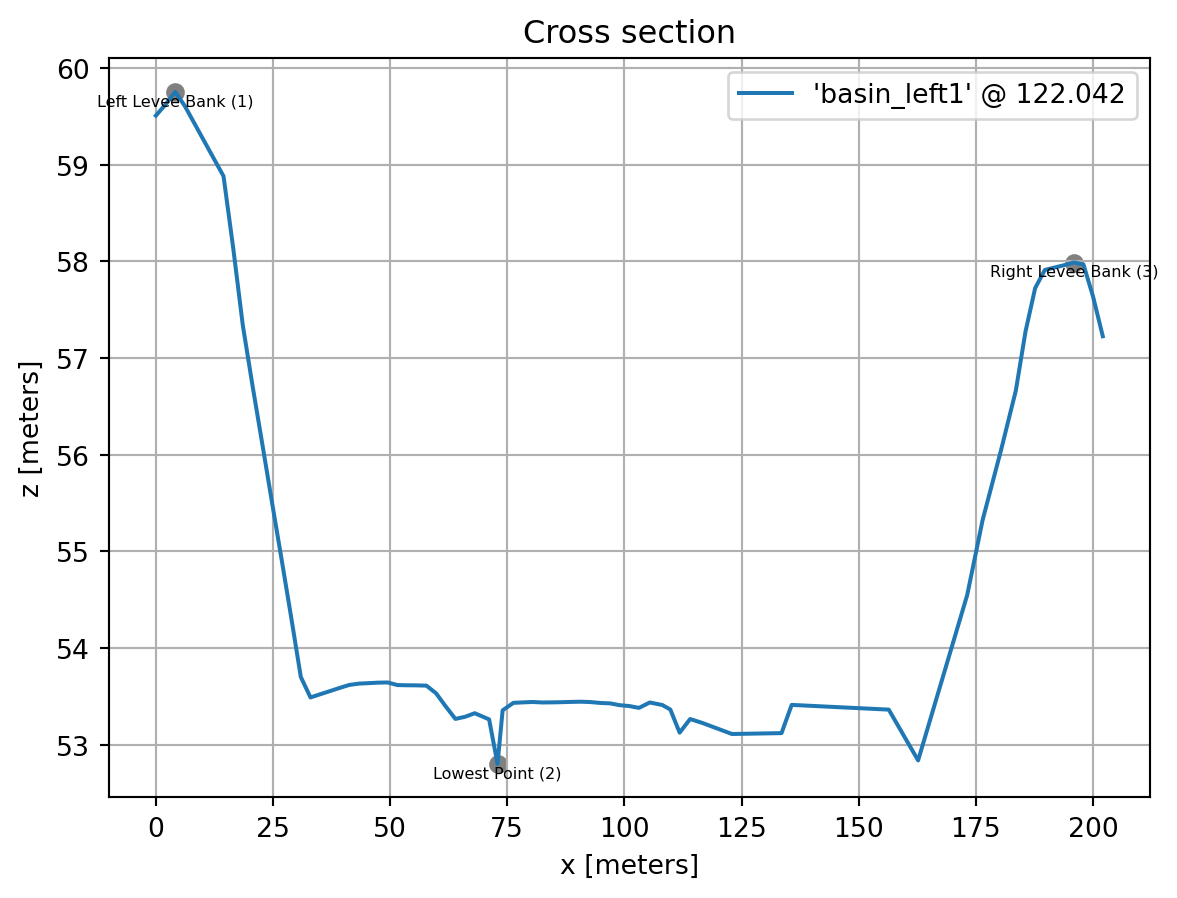
The raw data of a cross section can be accessed via the raw attribute.
df = xs.raw
df.head()| markers | marker_labels | x | z | resistance | |
|---|---|---|---|---|---|
| 0 | 0.000 | 4059.508 | 25.0 | ||
| 1 | 2.062 | 4059.624 | 25.0 | ||
| 2 | 1 | Left Levee Bank (1) | 4.124 | 4059.754 | 25.0 |
| 3 | 6.186 | 4059.607 | 25.0 | ||
| 4 | 14.435 | 4058.882 | 25.0 |
Raw data is modifiable by setting the raw attribute with a new DataFrame of the same column names.
df_modified = xs.raw
df_modified['z'] = df_modified['z'] + 1000
xs.raw = df_modified
xs.plot()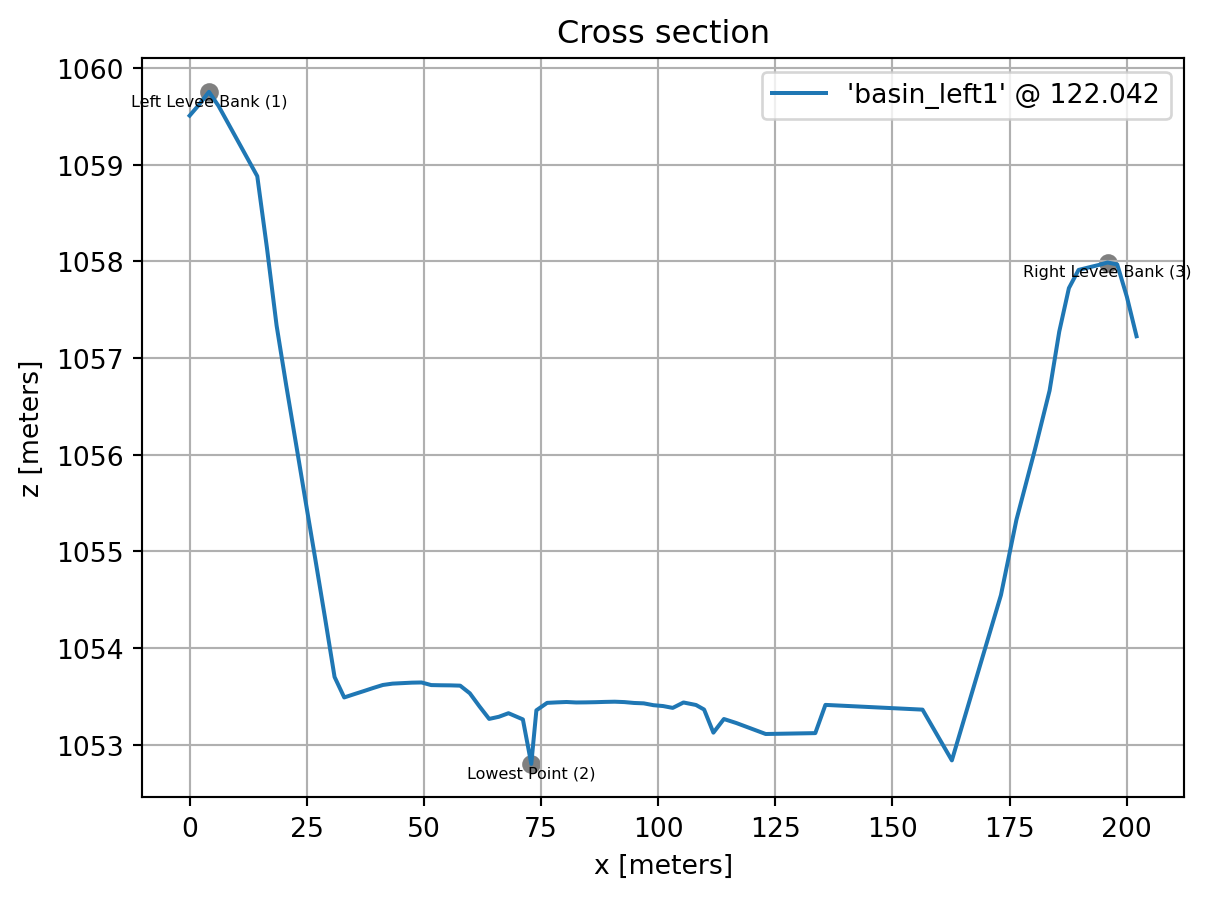
Markers can be viewed with the markers attribute.
xs.markers| marker | marker_label | x | z | |
|---|---|---|---|---|
| 0 | 1 | Left Levee Bank (1) | 4.124 | 5059.754 |
| 1 | 2 | Lowest Point (2) | 72.914 | 5052.803 |
| 2 | 3 | Right Levee Bank (3) | 195.897 | 5057.989 |
| 3 | 4 | Left Low Flow Bank (4) | 71.119 | 5053.263 |
| 4 | 5 | Right Low Flow Bank (5) | 74.003 | 5053.357 |
Set and unset markers with the set_marker and unset_marker methods. Alternatively, reassign a modified marker DataFrame like is done for raw data.
xs.set_marker(42, 50) # set a user-defined marker '42' at the closest point to x=50
xs.plot()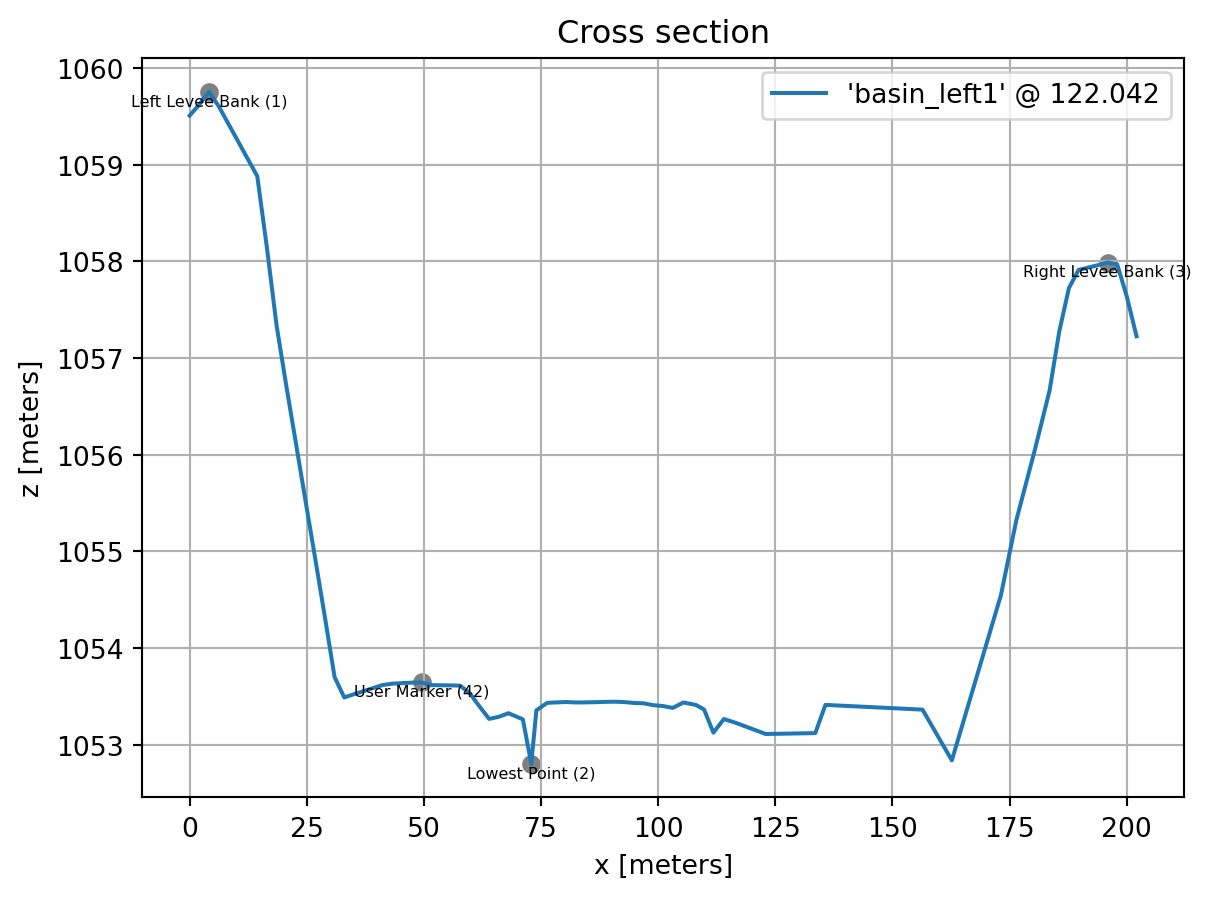
xs.unset_marker(42) # unset the user-defined marker '42'
xs.plot()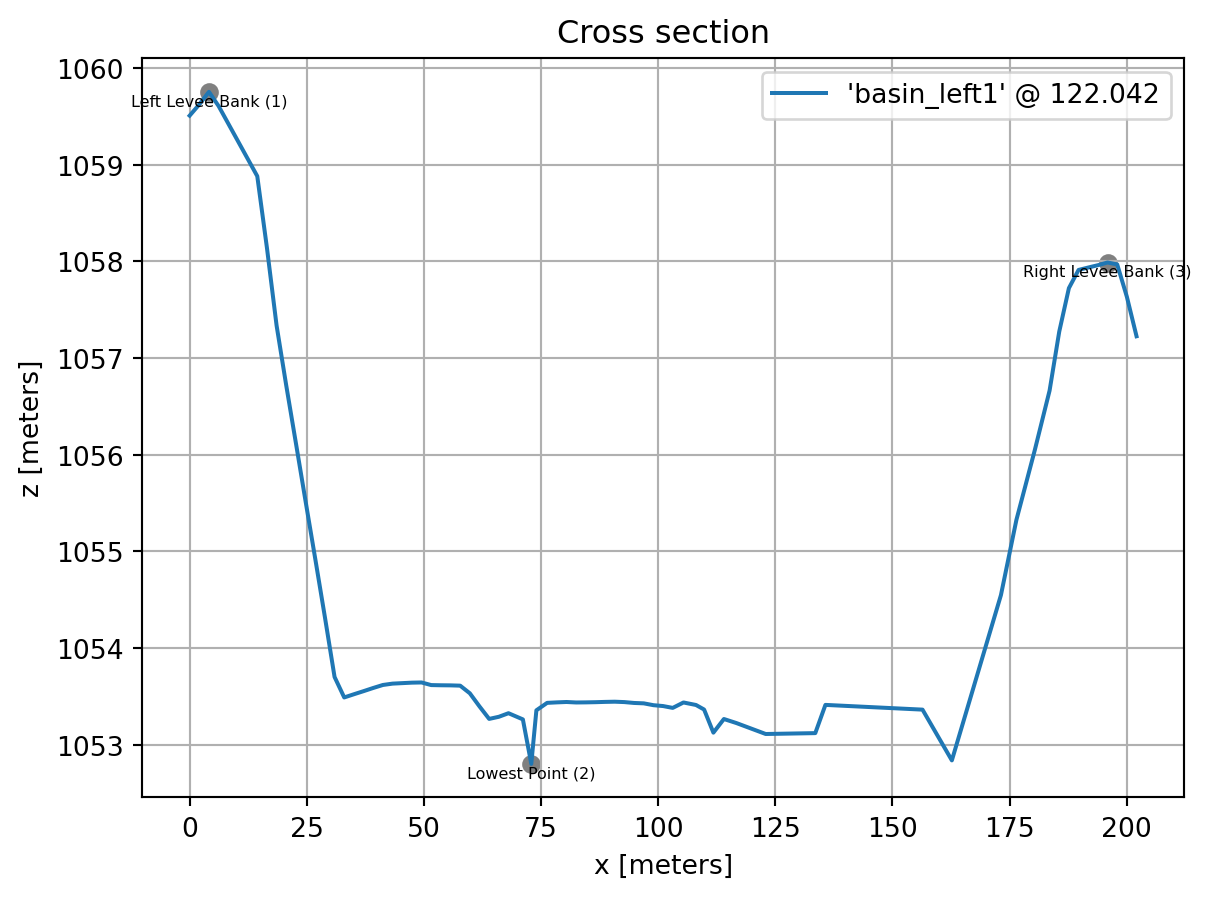
Processed data is accessible via the processed attribute.
df = xs.processed
df.head()| level | flow_area | radius | storage_width | additional_storage_area | resistance | conveyance_factor | |
|---|---|---|---|---|---|---|---|
| 0 | 5052.803000 | 0.000000 | 0.000000 | 0.000000 | 0.0 | 25.0 | 0.000000 |
| 1 | 5052.944857 | 0.160191 | 0.075978 | 2.743476 | 0.0 | 25.0 | 0.718409 |
| 2 | 5053.086714 | 0.790062 | 0.165315 | 6.136873 | 0.0 | 25.0 | 5.949433 |
| 3 | 5053.228571 | 3.633195 | 0.172199 | 29.866016 | 0.0 | 25.0 | 28.113531 |
| 4 | 5053.370429 | 9.264321 | 0.251109 | 50.128968 | 0.0 | 25.0 | 92.185348 |
Processed data is modifiable by setting the processed attribute with a new DataFrame of the same column names.
df_modified = xs.processed
df_modified['level'] = df_modified['level'] -500
xs.processed = df_modified
xs.processed.head()| level | flow_area | radius | storage_width | additional_storage_area | resistance | conveyance_factor | |
|---|---|---|---|---|---|---|---|
| 0 | 4552.803000 | 0.000000 | 0.000000 | 0.000000 | 0.0 | 25.0 | 0.000000 |
| 1 | 4552.944857 | 0.160191 | 0.075978 | 2.743476 | 0.0 | 25.0 | 0.718409 |
| 2 | 4553.086714 | 0.790062 | 0.165315 | 6.136873 | 0.0 | 25.0 | 5.949433 |
| 3 | 4553.228571 | 3.633195 | 0.172199 | 29.866016 | 0.0 | 25.0 | 28.113531 |
| 4 | 4553.370429 | 9.264321 | 0.251109 | 50.128968 | 0.0 | 25.0 | 92.185348 |
To recalculate processed datd based on the raw data, call the recompute_processed method.
xs.processed_allow_recompute = True
xs.recompute_processed()
xs.processed.head()| level | flow_area | radius | storage_width | additional_storage_area | resistance | conveyance_factor | |
|---|---|---|---|---|---|---|---|
| 0 | 5052.803000 | 0.000000 | 0.000000 | 0.000000 | 0.0 | 25.0 | 0.000000 |
| 1 | 5052.944857 | 0.160191 | 0.075978 | 2.743476 | 0.0 | 25.0 | 0.718409 |
| 2 | 5053.086714 | 0.790062 | 0.165315 | 6.136873 | 0.0 | 25.0 | 5.949433 |
| 3 | 5053.228571 | 3.633195 | 0.172199 | 29.866016 | 0.0 | 25.0 | 28.113531 |
| 4 | 5053.370429 | 9.264321 | 0.251109 | 50.128968 | 0.0 | 25.0 | 92.185348 |
Cross section collections can be extracted into a GeoDataFrame with to_geopandas.
gdf = xns.to_geopandas()
gdf.head()| location_id | chainage | topo_id | geometry | |
|---|---|---|---|---|
| 0 | basin_left1 | 2.004 | 1 | LINESTRING (385926.349 5715923.327, 385967.914... |
| 1 | basin_left1 | 33.774 | 1 | LINESTRING (385918.718 5715879.808, 386007.086... |
| 2 | basin_left1 | 80.945 | 1 | LINESTRING (385947.01 5715843.133, 386074.498 ... |
| 3 | basin_left1 | 122.042 | 1 | LINESTRING (385970.062 5715808.903, 386134.575... |
| 4 | basin_left1 | 166.107 | 1 | LINESTRING (385997.773 5715775.281, 386176.257... |
gdf.plot(column='location_id', cmap='tab20', legend=True)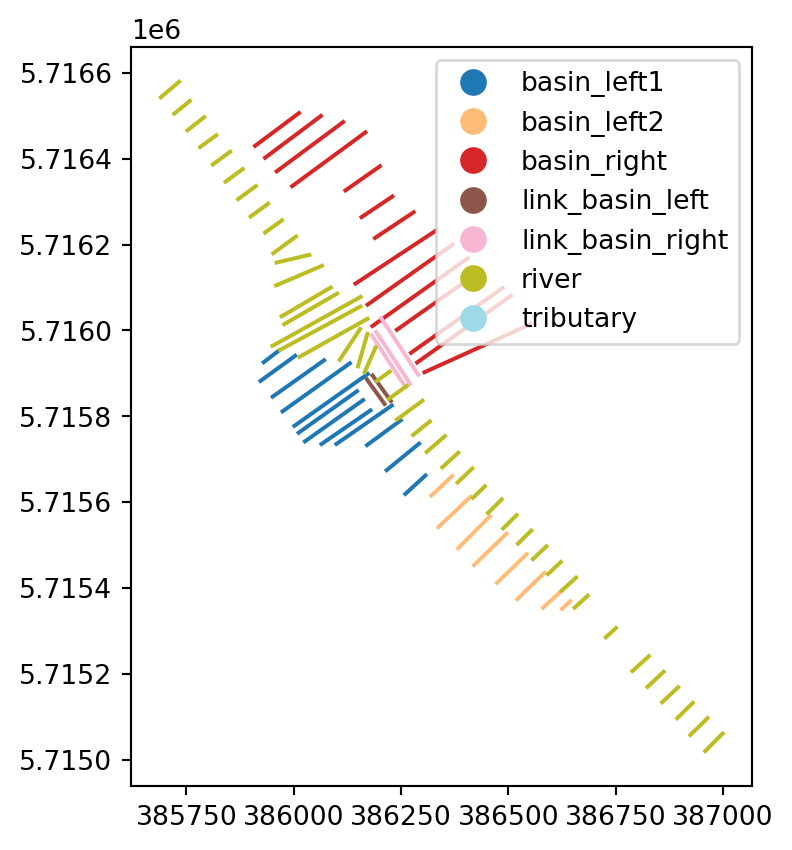
It is also possible to extract cross section markers as GeoDataFrames.
gdf = xns.to_geopandas(mode='markers')
gdf.head()| location_id | chainage | topo_id | marker | marker_label | geometry | |
|---|---|---|---|---|---|---|
| 0 | basin_left1 | 2.004 | 1 | 1 | Left Levee Bank (1) | POINT (385926.349 5715923.327) |
| 1 | basin_left1 | 2.004 | 1 | 2 | Lowest Point (2) | POINT (385955.309 5715945.473) |
| 2 | basin_left1 | 2.004 | 1 | 3 | Right Levee Bank (3) | POINT (385967.914 5715955.112) |
| 3 | basin_left1 | 33.774 | 1 | 1 | Left Levee Bank (1) | POINT (385924.812 5715884.216) |
| 4 | basin_left1 | 33.774 | 1 | 2 | Lowest Point (2) | POINT (385973.567 5715919.482) |
ax = xns.to_geopandas().plot()
xns.to_geopandas(mode='markers').plot(ax=ax, column='marker', markersize=9, legend=True)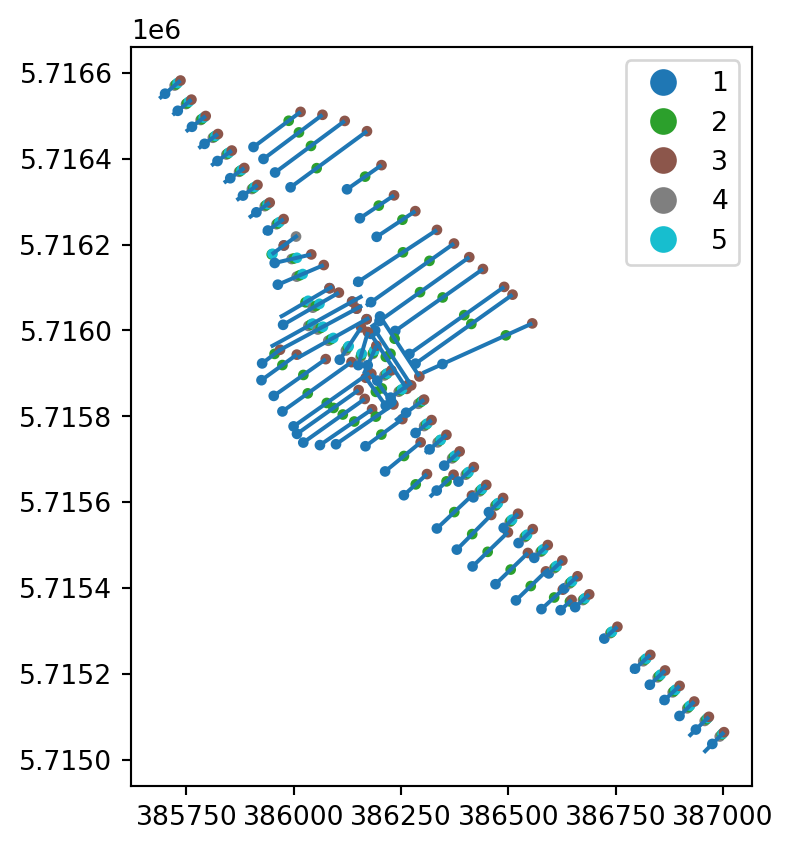
There are also several notebook examples available on our GitHub repositoryhttps://github.com/DHI/mikeio1d/tree/main/notebooks.