import mikeio1dEPANET - basic
Extract EPANET results for a water distribution system to a pandas DataFrame.
Overview
Tip
MIKE IO 1D treats EPANET (.res/.resx) and Res1D results in the same way, so you may also refer to Res1D examples.
Caution
Reading ‘.res’ files requires the accompanying ‘.inp’ file having the same name.
res = mikeio1d.open("../data/epanet.res")
res.info()Start time: 2022-10-13 00:00:00
End time: 2022-10-14 00:00:00
# Timesteps: 25
# Catchments: 0
# Nodes: 11
# Reaches: 13
# Globals: 0
0 - Water Demand (l/s)
1 - Head (m)
2 - Pressure (m)
3 - Water Quality (-)
4 - Flow (l/s)
5 - Velocity (m/s)
6 - Headloss Per 1000Unit (m)
7 - Average Water Quality (-)
8 - Status Code (-)
9 - Setting (-)
10 - Reactor Rate (-)
11 - Friction Factor (-)Plot network
res.network.to_geopandas().plot()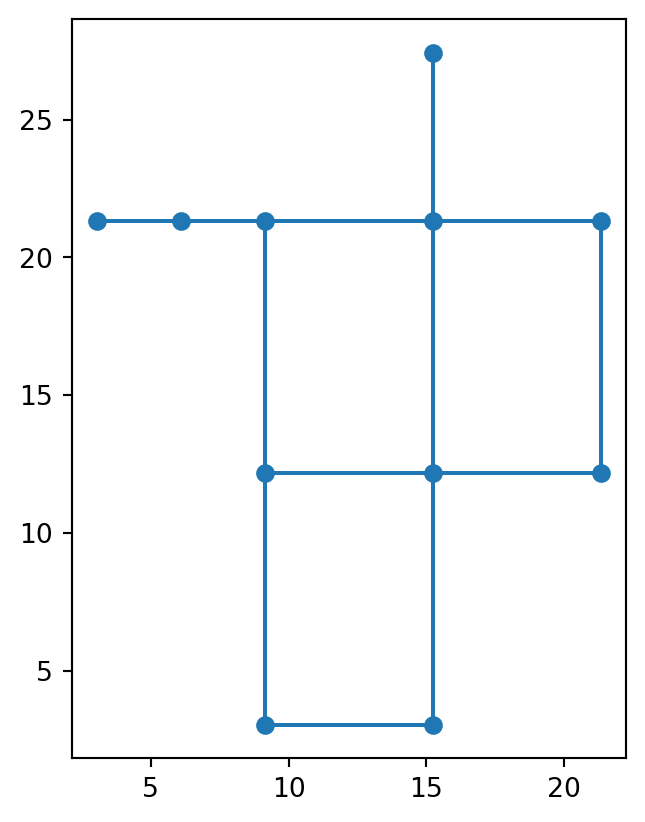
Explore network
res.reaches
<ResultReaches> (13)
Quantities (8)
- Flow (l/s)
- Velocity (m/s)
- Headloss Per 1000Unit (m)
- Average Water Quality (-)
- Status Code (-)
- Setting (-)
- Reactor Rate (-)
- Friction Factor (-)
Derived Quantities (0)
res.nodes
<ResultNodes> (11)
Quantities (4)
- Water Demand (l/s)
- Head (m)
- Pressure (m)
- Water Quality (-)
Derived Quantities (0)
Extract results to a DataFrame
df = res.read()
df.head()| Demand:10 | Head:10 | Pressure:10 | WaterQuality:10 | Demand:11 | Head:11 | Pressure:11 | WaterQuality:11 | Demand:12 | Head:12 | ... | ReactorRate:31 | FrictionFactor:31 | Flow:9 | Velocity:9 | HeadlossPer1000Unit:9 | AvgWaterQuality:9 | StatusCode:9 | Setting:9 | ReactorRate:9 | FrictionFactor:9 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2022-10-13 00:00:00 | 0.0 | 306.125000 | 89.716995 | 0.5 | 9.463531 | 300.298187 | 83.890175 | 0.5 | 9.463531 | 295.677277 | ... | 0.0 | 0.048410 | 117.737534 | 0.0 | -62.285000 | 0.0 | 3.0 | 1.0 | 0.0 | 0.0 |
| 2022-10-13 01:00:00 | 0.0 | 306.862823 | 90.454834 | 0.5 | 9.463531 | 301.137360 | 84.729355 | 0.5 | 9.463531 | 296.611542 | ... | 0.0 | 0.048470 | 116.627487 | 0.0 | -63.022831 | 0.0 | 3.0 | 1.0 | 0.0 | 0.0 |
| 2022-10-13 02:00:00 | 0.0 | 307.325562 | 90.917557 | 0.5 | 11.356236 | 301.663696 | 85.255707 | 0.5 | 11.356236 | 297.515137 | ... | 0.0 | 0.048168 | 115.925919 | 0.0 | -63.485558 | 0.0 | 3.0 | 1.0 | 0.0 | 0.0 |
| 2022-10-13 03:00:00 | 0.0 | 307.824982 | 91.416985 | 0.5 | 11.356236 | 302.231873 | 85.823860 | 0.5 | 11.356236 | 298.146301 | ... | 0.0 | 0.048195 | 115.163910 | 0.0 | -63.984989 | 0.0 | 3.0 | 1.0 | 0.0 | 0.0 |
| 2022-10-13 04:00:00 | 0.0 | 308.052460 | 91.644470 | 0.5 | 13.248942 | 302.490662 | 86.082672 | 0.5 | 13.248942 | 298.756622 | ... | 0.0 | 0.047632 | 114.815155 | 0.0 | -64.212471 | 0.0 | 3.0 | 1.0 | 0.0 | 0.0 |
5 rows × 148 columns
df = res.reaches.Flow.read()
df.head()| Flow:10 | Flow:11 | Flow:110 | Flow:111 | Flow:112 | Flow:113 | Flow:12 | Flow:121 | Flow:122 | Flow:21 | Flow:22 | Flow:31 | Flow:9 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2022-10-13 00:00:00 | 117.737534 | 77.866478 | -48.338314 | 30.407526 | 11.904859 | 1.850754 | 8.159774 | 8.883767 | 3.734274 | 12.060229 | 7.612776 | 2.574746 | 117.737534 |
| 2022-10-13 01:00:00 | 116.627487 | 76.997108 | -47.228264 | 30.166845 | 12.096551 | 1.899742 | 8.208762 | 8.861935 | 3.756105 | 11.841382 | 7.563788 | 2.552915 | 116.627487 |
| 2022-10-13 02:00:00 | 115.925919 | 73.462334 | -32.646851 | 31.107346 | 18.547157 | 3.341266 | 10.912090 | 10.234302 | 4.907347 | 9.516808 | 8.014970 | 2.663477 | 115.925919 |
| 2022-10-13 03:00:00 | 115.163910 | 72.857773 | -31.884855 | 30.949911 | 18.671141 | 3.374713 | 10.945538 | 10.223918 | 4.917730 | 9.369758 | 7.981522 | 2.653094 | 115.163910 |
| 2022-10-13 04:00:00 | 114.815155 | 69.403328 | -17.656246 | 32.162888 | 24.881876 | 4.783631 | 13.616260 | 11.704790 | 5.960466 | 7.209155 | 8.465311 | 2.872162 | 114.815155 |
Plot results
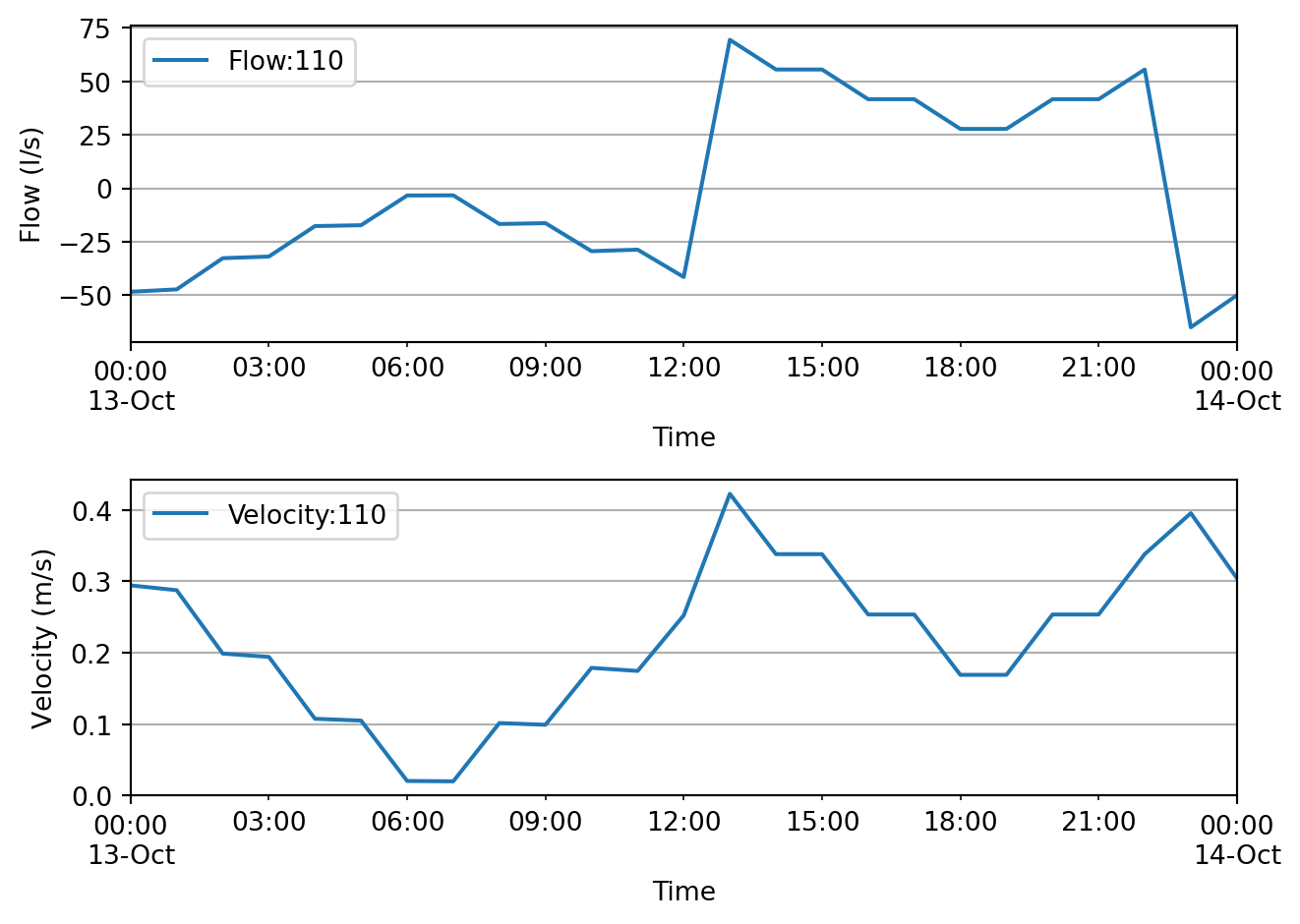
res.reaches['110'].Flow.plot()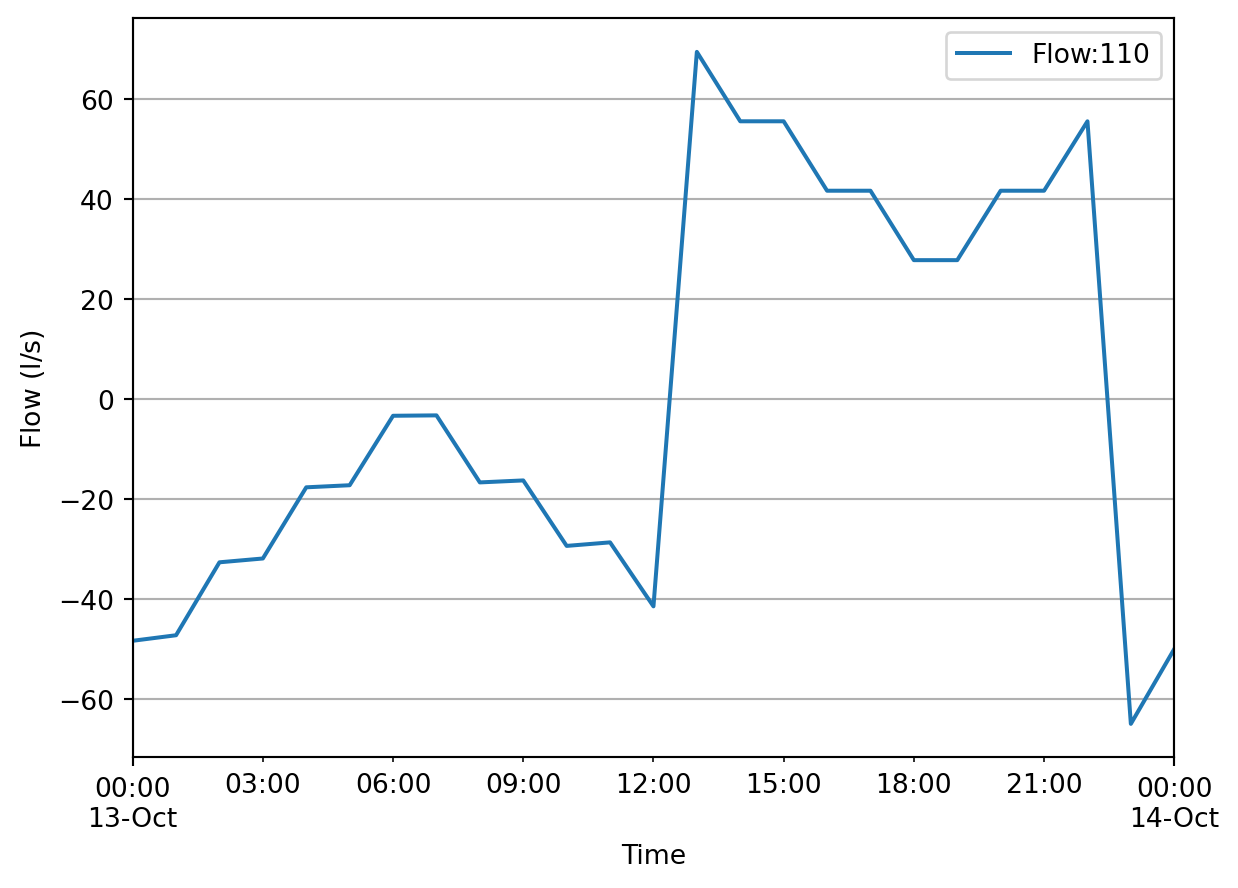
import matplotlib.pyplot as plt
fig, ax = plt.subplots(2)
res.reaches['110'].Flow.plot(ax=ax[0])
res.reaches['110'].Velocity.plot(ax=ax[1])
plt.tight_layout()